
扫码报名
多模态:谷歌发布新一代大模型Gemini,Gemini是全球范围内最先发布的多模态模型,是第一个在MMLU(大规模多任务语言理解)上超越人类专家的模型
- 板块介绍
- 板块资讯
- 强势股票
1、板块介绍
多模态是实现通用人工智能的必经之路,模态数据输入可帮助模型能力和用户体验提高,允许多模态数据输出也更符合真实世界需要。
按照处理的数据类型数量划分,AI模型可以划分为两类:
(1)单模态:只处理1种类型数据,如文本等
(2)多模态:处理2种及以上数据,可类比人脑同时对文本、声音、图像等不同类型信息进行处理。
多模态是实现通用人工智能的必经之路。相比单模态,多模态大模型在输入输出端的优势明显:
输入端:1)提升模型能力:高质量语言数据存量有限,且不同模态包含的信息具有互补性,多元的训练数据类型有助于提升通用大模型能力;2)提高用户体验:推理侧更低的使用门槛和更少的信息损耗。
输出端:更实用。1)可直接生成综合结果,省去多个模型的使用和后期整合;2)更符合真实世界生产生活需要,从而实现更大商业价值。

多模态大模型的技术脉络与前进方向:
(1)视觉模型:数据与算法往往同步发展,大型高质量数据集是模型突破重要基础,而近年视觉算法在泛化性、可提示性、生成质量和稳定性等方面突破将推动技术拐点到来以及爆款应用出现。其中2D图像生成引领视觉模型前进方向,由于2D图像生成是视觉模型中要求相对较低的领域,因此更容易实现技术突破,也出现了midjourney这类爆款应用,其兼顾使用门槛及生成效果,数据飞轮效应开始体现。文生图成本仍有优化空间,其中通用类应用由于需求相对刚性且有较强的付费意愿,盈利领先。3D资产生成、视频生成等领域受益于扩散算法成熟,但数据与算法难点多于图像生成,其中视频生成当前可类比2D图像生成的2021年(已有上亿规模数据集、扩散模型取得突破),且考虑到LLM对AI各领域的加速作用以及已出现较好的开源模型,2024年行业或取得更大的发展。3D资产生成则相对更加早期。
(2)听觉模型:数据仍有缺口,23年以来技术有所突破。未来技术成熟后可为企业/内容制造商/娱乐应用提供高性价比的音乐作品,或基于娱乐属性向C端收费。
(3)具身智能:相对远期,AI+机器人实现与现实世界交互。
行业现状
海外:OPENAI和谷歌在多模态领域布局的广度和技术先进程度上都处于领先地位,且都推出了表现较好的通用多模态大模型。而Stability.ai、midjourney、runway等垂类独角兽也对技术突破和产品创新发挥重要作用。
国内:国内数据、算法、算力均有劣势,但海外算法开源有利于国内技术追赶;考虑到中国科技公司在产品运营和迭代方面实力更强,技术与应用有望同步发展。国内大厂及大模型公司均积极布局多模态,有望结合生态优势进行变现;万兴科技、美图等AI视觉应用公司亦有望受益于底层技术进步。
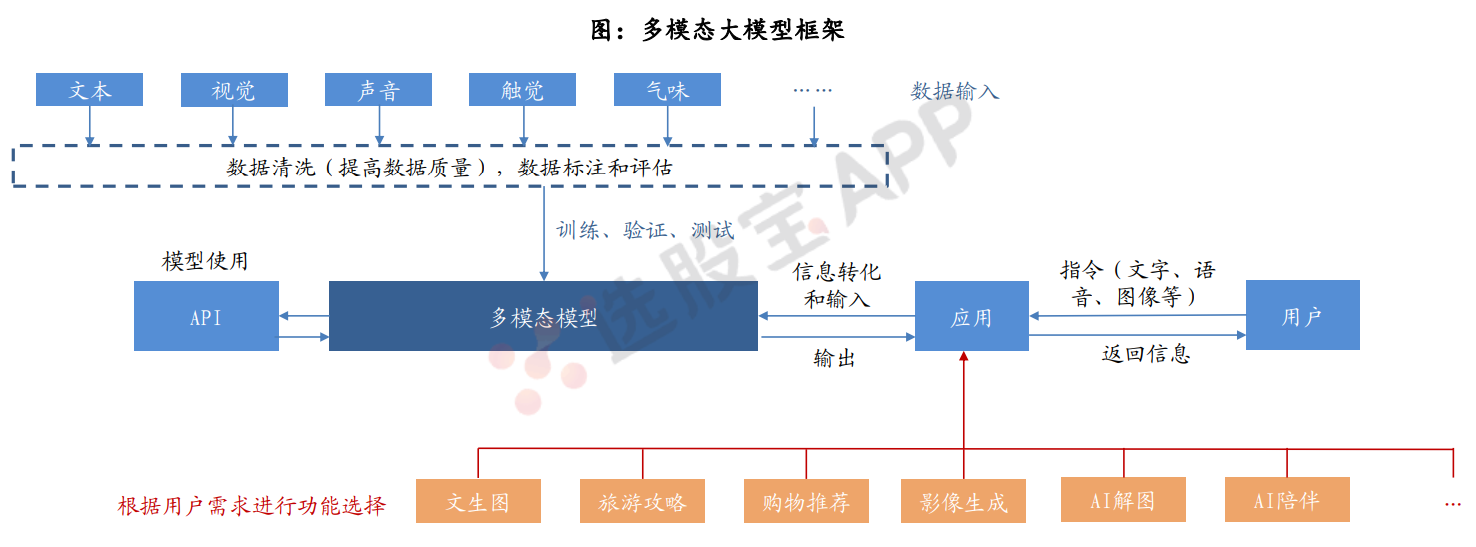
2、多模态大模型框架
2024-11-14 10:46
多模态:AI智能体再升级,OpenAI定档首个AI助理产品,机构称或将改变整体商业模式
到2030年前,AI智能体有望为全球经济贡献7万亿美元的价值。
2024-07-24 14:43
多模态:大模型打响出海发令枪,快手可灵国际版正式上线,多模态应用场景有望逐步丰富
快手可灵AI自6月6日开放申请以来,总申请人数已超百万人。
2024-05-13 10:05
多模态AI概念震荡回升,中胤时尚、网达软件涨停,万兴科技、佳发教育、因赛集团、值得买等跟涨
2024-05-11 21:04
《歌手2024》片头发布,万兴“天幕”大模型提供技术支持
据中证报,5月10日晚,《歌手2024》在时隔四年后再次回归,在湖南卫视、芒果TV双平台现场直播。《歌手2024》片头部分视频画面由万兴科技旗下万兴“天幕”大模型技术支持生成,充分展现出万兴“天幕”大模型文生视频的实力和行业应用实践方面的领先。
2024-04-21 22:41
清华大模型报告称,文心一言数学能力与Claude-3并列第一
最近,由清华大学基础模型研究中心联合中关村实验室研制的SuperBench大模型综合能力评测框架,正式对外发布2024年3月版《SuperBench大模型综合能力评测报告》。评测共包含了14个海内外具有代表性的模型,结果显示:文心一言4.0表现亮眼,与国际一流模型水平接近,且差距已经逐渐缩小,名副其实为国内头部模型。在语义理解中的数学能力上,文心一言4.0与Claude-3并列全球第一;GPT-4系列模型位列第四五,其他模型得分在55分附近较为集中,明显落后第一梯队;而在语义理解中的阅读理解能力上,文心一言4.0超过GPT-4 Turbo、Claude-3以及GLM-4拿下榜首。
2024-04-17 17:28
谷歌开发者大会下月举行,去年发布了Gemini,这次可能包括两大重点
2024-04-14 22:43
xAI公司展示首个多模态模型,有望为下游赋能
Grok-1.5 Vision能处理文档、图表、截图和照片中的内容。今日重要性:✨
2024-04-11 13:06
多模态AI概念持续走强,三六零午后涨停,昆仑万维、值得买、引力传媒、华策影视等涨幅靠前,消息面上,近日,AIwatch.ai发布“全球AI产品增速黑马榜”,三六零两款AI产品进入前十,其中360AI搜索居榜首,3月访问量环比增加1677%
2024-03-19 20:23
半导体行业或有新动作,机构称目前已处于周期底部;我国首个制氢加氢一体站标准发布,本月行业或还存一预期 | 3月20日早知道
全球半导体销售额连续三个月同比增长,中国区增速最快。
2024-03-19 16:10
多模态:阿里两大重磅产品加码多模态,机构称行业新一轮浪潮蓄势待发
2024年文生视频有望在时间长度、画面清晰度、内容逼真程度等方面实现显著迭代,打开商业化应用空间。
2024-03-11 10:19
多模态AI概念股探底回升,三人行2连板,捷成股份、因赛集团、苏州科达、世纪天鸿等跟涨
2024-03-05 09:28
AI大模型:AI模型龙头地位一夜易主,GPT-4被全面碾压,机构预计有望加速带来新一轮生产力变革
AI大模型在实际应用场景中的加速渗透。
2024-02-29 09:41
多模态概念股快速反弹,国新文化涨停,开普云、宣亚国际、因赛集团涨超5%,天娱数科、竞业达、汉王科技等跟涨
2024-02-18 19:40
全球AI进展刷屏,机构押注其或成全球经济复苏的“诺亚方舟”,有望成应用真正元年;海外巨头新高+热辣滚烫点火,这一概念假期又爆了 | 2月19日早知道
春节长假期间,海外AI相关进展持续刷屏。
2023-12-26 13:33
多模态AI概念股走势低迷,云从科技跌超7%,昆仑万维、软通动力、天娱数科、新华网、宣亚国际等跌超5%
| ID | 股票名称 | 涨幅% | 现价 | 换手率% | 总市值 | 炒作逻辑 |
|---|

 VIP复盘网
VIP复盘网
