
没想到,文小言接入推理模型的大更新背后,百度还藏了一手“质变”级技术大招???

Talk is cheap,直接来看Demo:
士别三日,文小言不仅能讲重庆话了,还是成了哄娃的一把好手,被花式打断照样应对如流:
实测下来,Demo不虚。这个全新语音对话功能,确实更有人味儿了,还是能紧贴当下实事的那种——
只是让Ta推荐周末放松去处,Ta自己就能主动结合当前4、5月份的现实时间,给出更加合理的建议。
划重点,这是免费的。现在你也一样可以打开手机里的文小言,直接体验这一全新升级的实时语音对话功能。
但!是!
如果单说语音体验,那还真不是这个“大招”的重点。关键是,这回百度还透露了更多技术细节。
我们仔细一看,还真是有意思了。

首先,上来就是一个行业首创:以上实时语音对话效果,由百度全新推出的端到端语音语言大模型实现,这是行业首个基于Cross-Attention的跨模态语音语言大模型。
有何不同?站在用户体验的角度来说,就是语音合成延迟更低,对话更真实有情感。
而更重要的一点是,这么个新模上线,文小言在语音问答场景中的调用成本,最高能降低90%!直接打掉了工业级落地的门槛。
(再也不怕模型厂流量大到挂我服务.jpg)
我们注意到,百度语音首席架构师贾磊,其实用到了“质变”这个词:
百度端到端语音语言大模型是有质变的,不是单纯把文本大模型用到语音领域。
语音场景有其独特之处。此前,大家没有充分挖掘这个应用场景的不同,还是按照把文本大模型用到语音场景的路线,把速度加快一下,工程优化一下。
我们的创新架构,让大模型在语音场景中的应用实现了极低成本,更有利于大模型普及。
就是说,这一次语音技术的更新,不仅仅是工程上的技巧,百度正在通过技术创新,打通大模型落地语音场景的工业级应用新范式。
行业首个基于Cross-Attention的端到端语音语言模型
话说到这了,咱们就来一起仔细扒一扒背后技术方案,看看究竟是怎么一回事。
先给大家划个重点:
熟悉大模型的小伙伴都知道,KV cache能够加速自回归推理,但其在存储和访问上的开销,也会随着序列长度和模型规模增大而爆炸式增长。
因此在保证模型性能的前提下,降低KV cache,对于大模型应用来说,是提升推理效率、降低成本的一大关键。
百度此次推出的基于Cross-Attention的端到端语音语言模型,重点就在于此。
具体来说,百度做了以下创新:
业内首创的基于Cross-Attention的跨模态语音语言大模型
Encoder和语音识别过程融合,降低KV计算
Decoder和语音合成模型融合
创新提出基于Cross-Attention的高效全查询注意力技术(EALLQA),降低KV cache
我们一项一项展开来看。
基于Cross-Attention的跨模态语音语言大模型
整体上,这个端到端语音语言大模型是基于Self-Attention的文心预训练大模型,采用自蒸馏的方式进行后训练得到。训练数据为文本和语音合成数据的混合。整个模型采用MoE结构。
关键点在于,在端到端语音识别中,声学模型也是语言模型,因此在整合语音识别和大语言模型的过程中,能够通过将大语言模型中的Encoder和语音识别的过程融合共享,达到降低语音交互硬延迟的目的。
而在语音领域,Cross-Attention天然具有跨模态优势:Decoder会显式地将Encoder输出纳入注意力计算,使得Decoder在每一个解码步骤都能动态访问最相关的输入向量,从而充分地对齐和利用跨模态信息。

基于Cross-Attention的高效全查询注意力技术(EALLQA)
不过,Cross-Attention的引入带来了另一个问题:MLA的位置编码技术,在Cross-Attention中容易出现不稳定的现象。
为此,百度语音团队提出了高效全查询注意力技术(EALLQA):
采用创新的隐式RNN两级位置编码,训练时是在128空间上的MHA,推理时是在模型各层共享的512空间上的MQA(AllQA)。既充分利用了有限的训练资源,也极大地降低了推理成本。

从具体效果上来说,EALLQA技术能使KV cache降至原来的几十分之一,并将Cross-Attention的最近上一个问题的KV计算降至原来的十分之一,极大降低了语音交互时用户的等待时间和模型推理成本。

降低成本的另一个关键,则是Encoder和语音识别系统的融合:对Query理解的模型较小,能极大减少KV计算。
流式逐字的LLM驱动的多情感语音合成
训练、推理成本的降低之外,端到端语音语言大模型还通过语音模型和语言模型的融合,实现了文体恰当、情感契合、自然流畅的合成音频的生成。
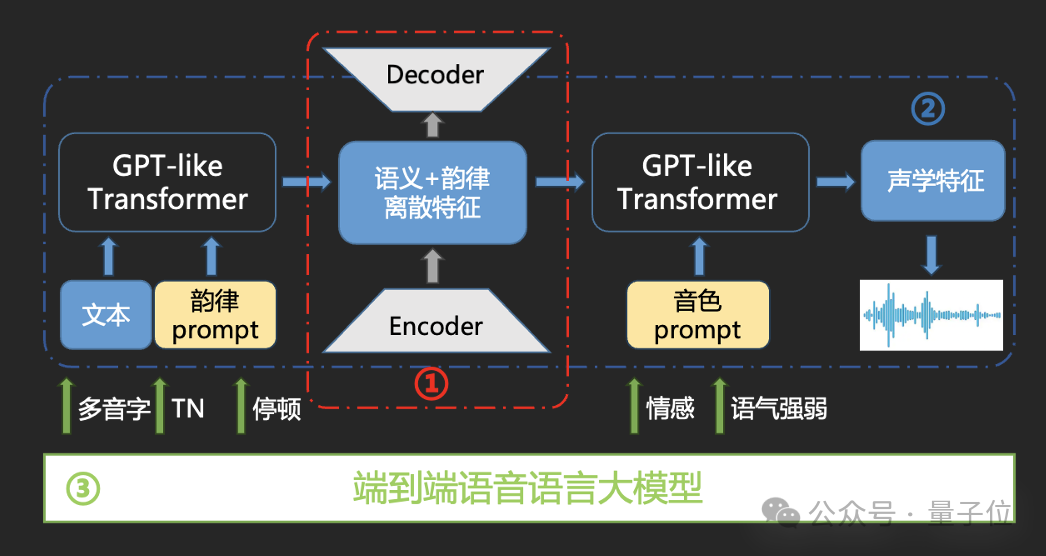
一方面,研发团队通过大规模文本-语音数据自监督预训练,构建语义 韵律的离散化特征空间,通过双层GPT-like Transformer,实现了韵律、音色双Prompt控制机制。
另一方面,在此基础之上,研发团队推出了语音语言大模型与合成一体化流式逐字合成。
有别于传统语音合成的整句输出,流式逐字相当于一个字一个字地合成。在这个过程中,语言大模型能够指导语音模型去生成情感、停顿,识别多音字等等,实现更为拟人、自然的语音合成效果。
需要注意的是,人耳接收信息实际上是一个字一个字地接收,但对于AI而言,如果1个token接1个token的输出,就需要解决并发的问题,以使MoE架构最大程度发挥作用。
流式逐字合成要解决的核心问题,就是在适配人听力的基础上,实现高并发。
通过引入流式逐字合成,百度端到端语音语言大模型有效提升了语音交互的响应速度,同时降低了语音交互领域使用大模型成本。与大模型融合的TTS文体风格情绪控制,还可以根据文本输出自适配的情况,情感覆盖达到17种。

简单总结一下,百度的端到端语音语言大模型,一方面是重点解决了大模型应用于语音交互场景成本高、速度慢的问题。
另一方面,大语言模型带来的语义理解等能力,也解决了传统语音交互中,同音字识别、打断、真实情感等痛点。
贾磊透露,目前,整个端到端语音语言大模型在L20卡上即可部署,在满足语音交互硬延迟要求的情况下,双L20卡并发可以做到数百以上。
极低成本是关键
说了这么多,最主要的关键词其实就是:低成本。
在与贾磊的进一步交流中,他向我们强调了降低成本的重要性:
极低成本就意味着大规模工业化变得非常容易。
2025年,大模型的核心并不在于展示什么新功能,而是能以多快速度真正应用到国计民生中去。
在不考虑计算资源的情况下,实时语音交互有其他路径可以实现,但“我们今天是第一个做到跨模态端到端极低成本解决语音问题的”。

贾磊还表示,希望语音领域的这一突破创新能被行业更多地关注到。
我们想要把核心技术分享出去,告诉大家我们是怎么做的,以此推动整个领域的爆发。
事实上,不仅是百度,在包含语音的大模型能力对外输出上,国内外厂商都将价格视作突破口。
OpenAI就专门从性价比出发,推出了GPT-4o mini audio,希望以更低廉的价格打入语音应用市场。
2025年,基础模型方面,模型厂商在推理模型上争相竞逐,而其带来的最直接的影响之一,是人们对于大模型应用加速爆发预期的持续升温。在这个过程中,我们可以看到,站在模型厂商的角度,更多的模型在被开源,更多的服务在免费开放,用户认知、关注的争夺之中,成本本身正在变得更加敏感。
更不用提成本即是大规模应用的关键:不仅是在模型厂商们的APP上,还要进一步走进手机、汽车……
正如DeepSeek在基础模型领域搅动池水,现在,百度也在语音领域迈出关键一步。
成本,正在成为当前阶段模型厂商获得主动权的重要突破口。
One More Thing
从文小言的语音交互架构图中还可以看到,它像是个语音版百度搜索。

正如文章开篇我们体验到的,文小言能结合当前的季节对用户问题给出更合理的回答。实际上,在语音功能中,文小言已经支持多垂类助手能力,包括天气、日历查询、单位换算、股价股票等信息查询内容,共计38个垂类。
还支持DeepQA RAG问答,包含百度查询等时效性问答内容,能结合检索结果,做到更精准的指令跟随;支持DeepQA非RAG问答,包含常识问答等非时效性问答内容。
“有问题,问小言”的这个“问”字,确实是越来越接近人类原本的交互习惯了。
这实际也是产业趋势的一种映射——
之前都是大模型技术探索,需要不断适配才能落地产品、形成应用,最后被用户感知。
现在这是大模型技术和产品应用,几乎在同时对齐,技术推进的时候就瞄准了应用场景,应用场景也能催生更适合的技术,不是锤子找钉子,而是锤子钉子同时对齐。
大模型依然是AI世界的核心,但天下却正在变成应用为王的天下。
百度,或者说中国AI玩家,开始找到自己的节奏了。

 VIP复盘网
VIP复盘网
