
投资要点
►AI需求推动运力持续增长,互联方案重要性显著提升
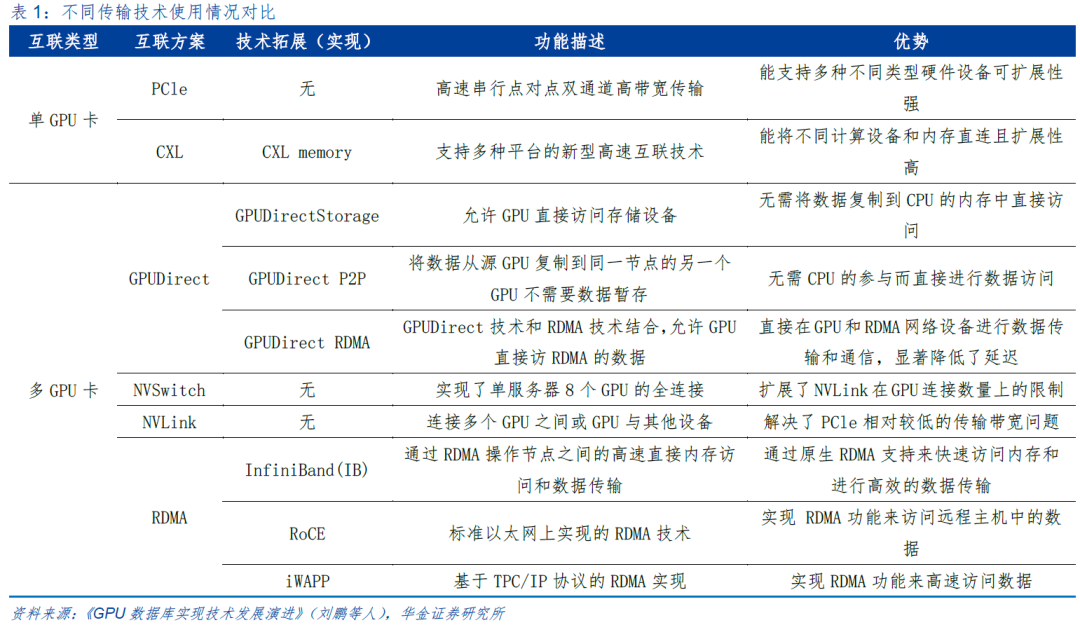
AI 相关应用的快速发展推动“算力”和“存力”需求快速增长的同时,对“运力”也提出更高需求。AI计算集群互联通信能力系统性的构建主要包括裸片间互连、片间互联和机间互联三大方面。目前常见的片间互联方案包括PCle、NVLink、CXL、GPUDirec、RDMA等。PCIe作为CPU和GPU之间的数据传输方案,经过数次迭代,已达到近百GB的数据传输速率,同时具有较强的可拓展性。然而,这依然无法满足高速数据带宽的需求。除此之外,由于GPU连接数量的增加,GPU之间的通信技术如GPU Direct、NVLink和RDMA等技术被大量应用。NVLink的出现在一定程度上解决了PCIe带宽和传输瓶颈的问题。GPUDirect、RDMA和InfiniBand通常在分布式系统和多GPU集群中有大量的应用。CXL具有更好的灵活性和可扩展性,能支持不同设备之间的混合连接。
►互联技术加速迭代,刺激运力芯片需求
1)PCIe Retimer芯片:该芯片可有效提升PCIe信号的完整性,增加高速信号的有效传输距离。到PCIe 5.0时代,PCIe Retimer芯片已成为行业主流解决方案。一台典型配置8块GPU的主流AI服务器需要8颗或16颗PCIe Retimer芯片。未来,PCIe Retimer芯片的市场空间将随着GPU需求量的增加而持续扩大。2)CXL MXC 芯片:该芯片是基于CXL 协议的高带宽高容量内存扩展模组的核心芯片,主要应用于内存扩展及内存池化领域,可大幅扩展内存容量和带宽,满足高算、AI等数据密集型应用日益增长的需求。3)MRCD/MDB芯片:MRDIMM可满足AI及大数据应用对更高带宽内存的需求。MRCD、MDB芯片是MRDIMM的核心逻辑器件,每个MRDIMM模组需要搭配1颗MRCD芯片及10颗MDB芯片。随着MRDIMM未来渗透率的提升,将带动MRCD/MDB(特别是 MDB)芯片需求大幅增长。
►建议关注
►风险提示
下游需求复苏低于预期,算力基础设施建设进度低于预期,相关厂商研发进程不及预期,系统性风险等。



一、AI需求推动运力持续增长,互联方案重要性显著提升
AI 相关应用的快速发展正推动“算力”和“存力”需求快速增长,系统需要更高、更强的算力以及带宽更高、容量更大的内存。在“算力”和“存力”增长的同时,对“运力”也提出更高需求。
“运力”是指在计算和存储之间搬运数据的能力。在AI大模型业务场景下,模型参数需要通过高速互联网络在不同的服务器间、卡间进行同步交互,且随着模型参数规模的增长,传输数据量持续增长,需要更加高速、实时、可靠的算内网络支持。AI需求正推动运力持续提升。
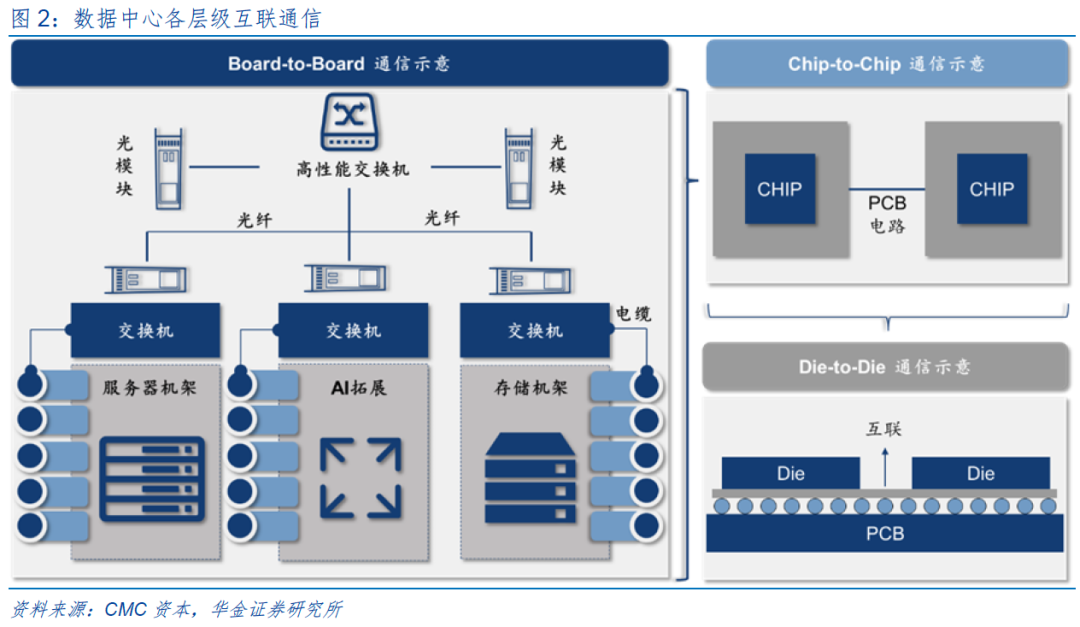
AI计算集群的互联通信能力由内到外可分为三大层级:1)Die-to-Die(裸片间)互联:发生在芯片封装内,实现芯片内部不同功能模块间的数据交换;2)Chip-to-Chip(片间)互联:实现服务器内部,主板上不同芯片间(如CPU-GPU,GPU-GPU)的数据通信;3)Board-to-Board(机间)互联:在服务器外部的通信,实现服务器-交换机、交换机-交换机之间的数据传输,并层层叠加形成数据中心集群的组网架构。
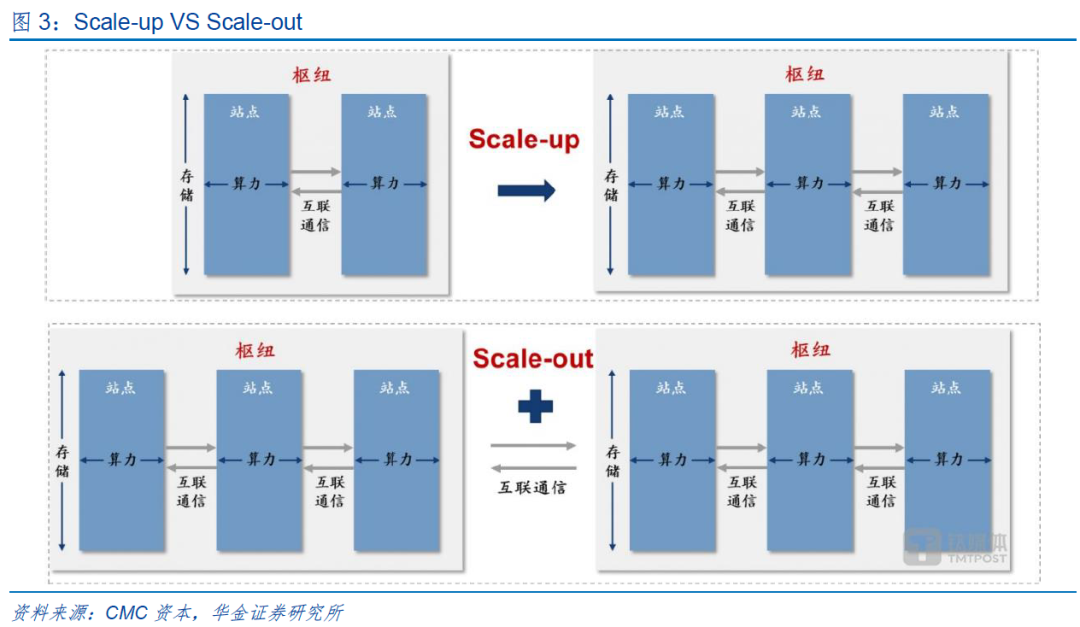
数据中心性能提升方式主要有两种:1)Scale-up(向上/垂直扩展):通过增加单个系统的资源(如芯片算力、存力)以提升性能,即让一个单一的系统变得更加强大;英伟达通过集成36颗GB200x芯片推出的DGX GB200系统。2)Scale-out(横向/水平扩展):通过增加更多的相同或相似配置的系统来分散工作负载,即添加更多的独立系统来共同完成任务;如英伟达DGX SuperPOD,可集成至少8个甚至更多DGX GB200系统,并通过不断的拓展来实现数万颗GB200芯片的聚集。
PCIe作为CPU和GPU之间的数据传输方案,经过数次迭代,已达到近百GB的数据传输速率,同时具有较强的可拓展性。然而,这依然无法满足高速数据带宽的需求。除此之外,由于GPU连接数量的增加,GPU之间的通信技术如GPU Direct、NVLink和RDMA等技术被大量应用。NVLink的出现在一定程度上解决了PCIe带宽和传输瓶颈的问题,但是在较低速的连接需求中,PCIe依然是一种适合的解决方案。GPUDirect、RDMA和InfiniBand通常在分布式系统和多GPU集群中有大量的应用。CXL具有更好的灵活性和可扩展性,能支持不同设备之间的混合连接。
二、互联技术加速迭代,刺激运力芯片需求
1、PCIe Retimer 芯片
PCIe 协议是一种高速串行计算机扩展总线标准,自2003年诞生以来,PCIe互连技术发展迅速,传输速率基本上实现了每3-4年翻倍增长,并保持良好的向后兼容特性。PCIe协议已由PCIe 4.0发展为PCIe 5.0,传输速率已从16GT/s提升到32GT/s,到PCIe 6.0,传输速率将进一步提升到64GT/s。
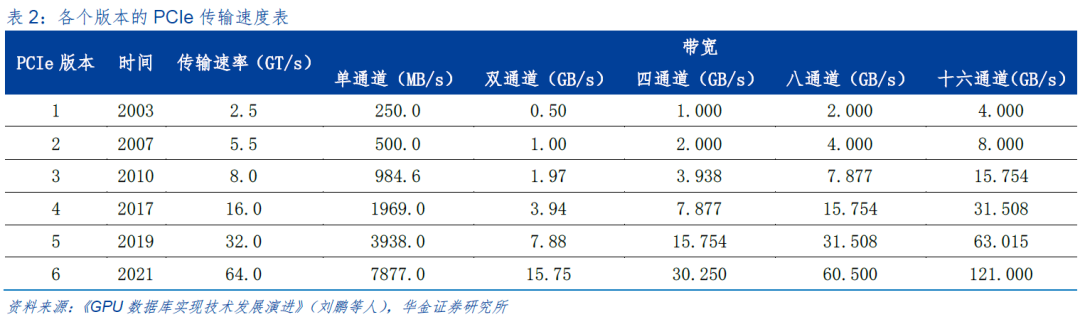
PCIe作为最常见的高速互连标准之一,被广泛用于CPU、GPU之间的高速互连。随着PCIe协议传输速率的快速提升,并依托于强大的生态系统,平台厂商、芯片厂商、终端设备厂商和测试设备厂商的深入合作,PCIe已成为主流互连接口,全面覆盖了包括PC机、服务器、存储系统、手持计算等各种计算平台,有效服务云计算、企业级计算、高性能计算、人工智能和物联网等应用场景。
然而,一方面随着应用不断发展推动着PCIe标准迭代更新,速度不断翻倍,另一方面由于服务器的物理尺寸受限于工业标准并没有很大的变化,导致整个链路的插损预算从PCIe3.0时代的22dB增加到了PCIe 4.0时代的28dB, 并进一步增长到了PCIe 5.0时代的36dB。
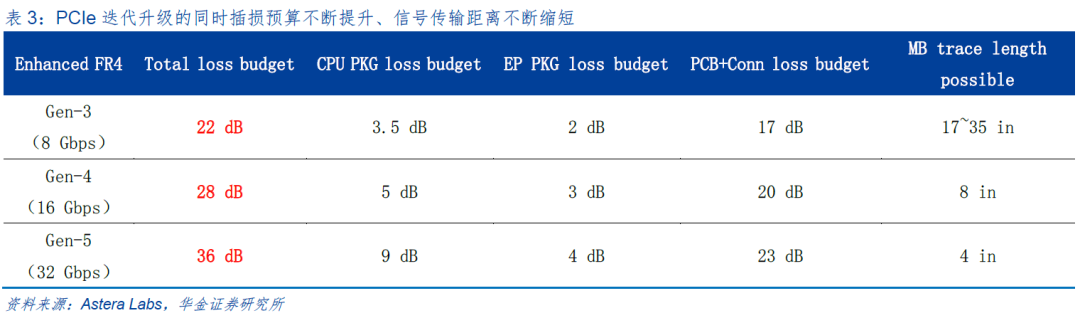
如何解决PCIe信号链路的插损问题、提高PCIe信号传输距离是业界面临的重要问题。一种思路是选用低损PCB,但价格高昂,仅是主板就可能会带来较大的成本增加,且并不能有效覆盖多连接器应用场景。

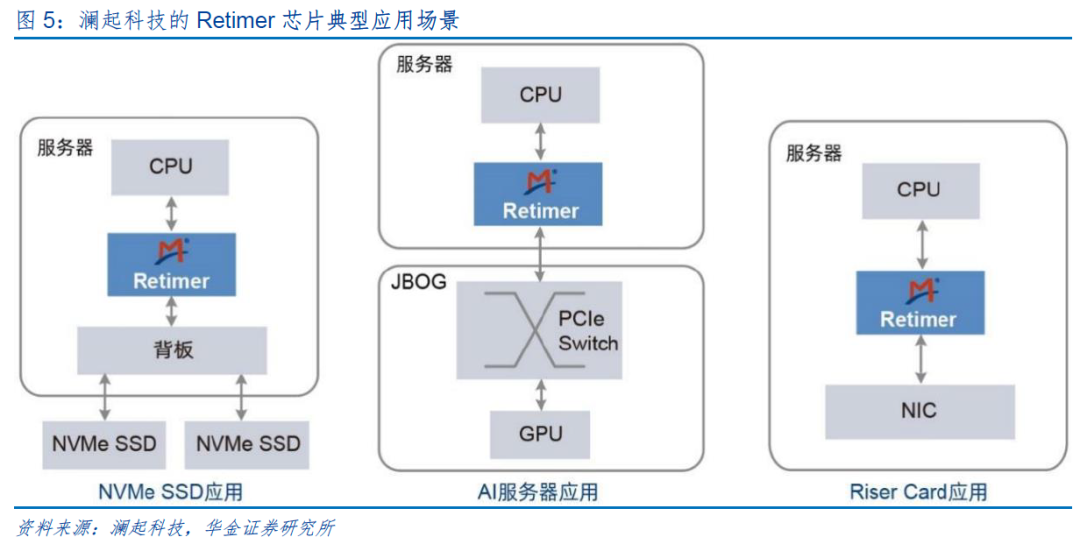
另一种思路是引入适当的链路扩展器件如Retimer。PCIe Retimer芯片采用模拟信号和数字信号调理技术、重定时技术,来补偿信道损耗并消除各种抖动的影响,从而提升PCIe信号的完整性,增加高速信号的有效传输距离。

PCIe Retimer芯片是适用于PCIe高速数据传输协议的超高速时序整合芯片。PCIe Retimer 芯片作为PCIe协议升级迭代背景下新的芯片需求,其主要解决数据中心、服务器通过PCIe协议在数据高速、远距离传输时,信号时序不齐、损耗大、完整性差等问题。相比于市场其他技术解决方案,现阶段Retimer芯片的解决方案在性能、标准化和生态系统支持等方面具有一定的比较优势,未来根据系统配置,Retimer芯片可灵活地切换PCIe或CXL模式,更受用户青睐。
随着传输速率从PCIe 4.0的16GT/s到PCIe 5.0的32GT/S,再次实现翻倍,Retimer芯片技术路径的优势更加明显。根据目前行业发展趋势,到PCIe 5.0时代,PCIe Retimer芯片已成为行业主流解决方案。
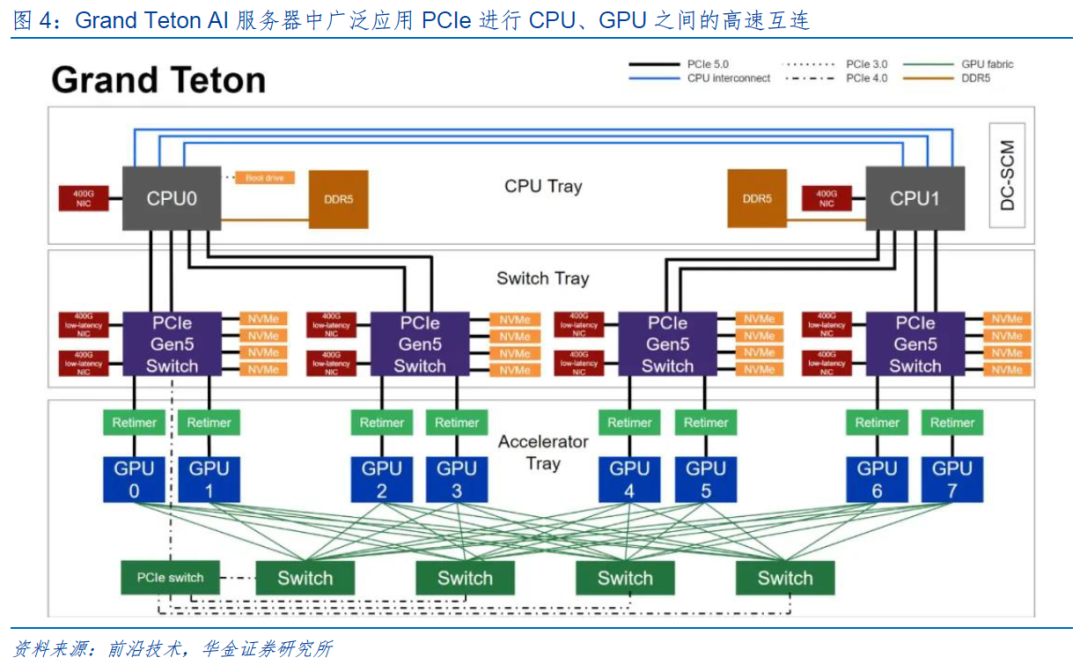
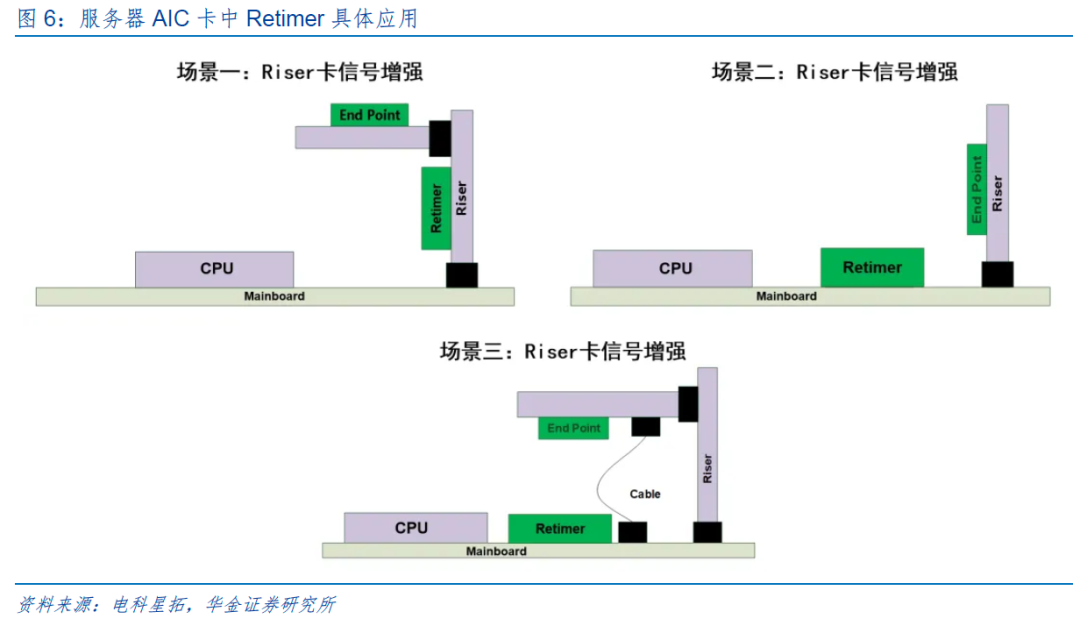
服务器AIC卡:AIC卡作为扩展卡,通常负责处理额外的计算任务,如AI加速、网络加速等。由于其需要与服务器主板进行高速数据交换,因此信号质量和传输效率直接影响到整个系统的性能。Retimer能够在高速信号链路中重新定时信号,消除信号反射和噪声的影响,从而确保数据在传输过程中的完整性和一致性。特别是在需要长距离传输的场合下,Retimer的作用更为明显,能显著降低误码率,提高系统可靠性。
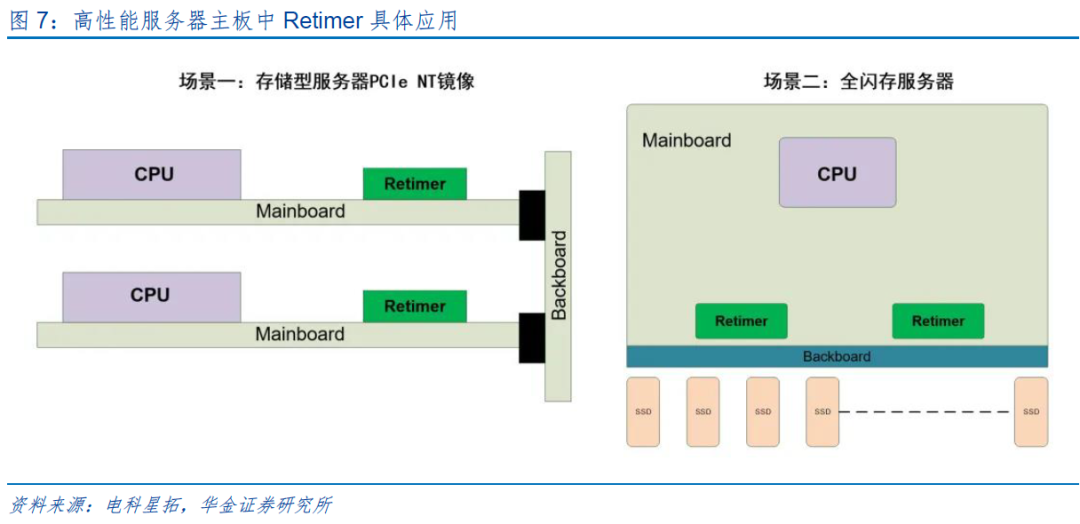
高性能服务器主板:随着服务器核心数量的增加及带宽需求的增长,主板上的信号走线愈发复杂,给信号传输带来巨大压力。通过集成Retimer芯片,主板可在信号传输路径的关键节点上进行信号再生,补偿信号损失,维持信号强度,进而保障服务器内部各组件之间高效协同工作。
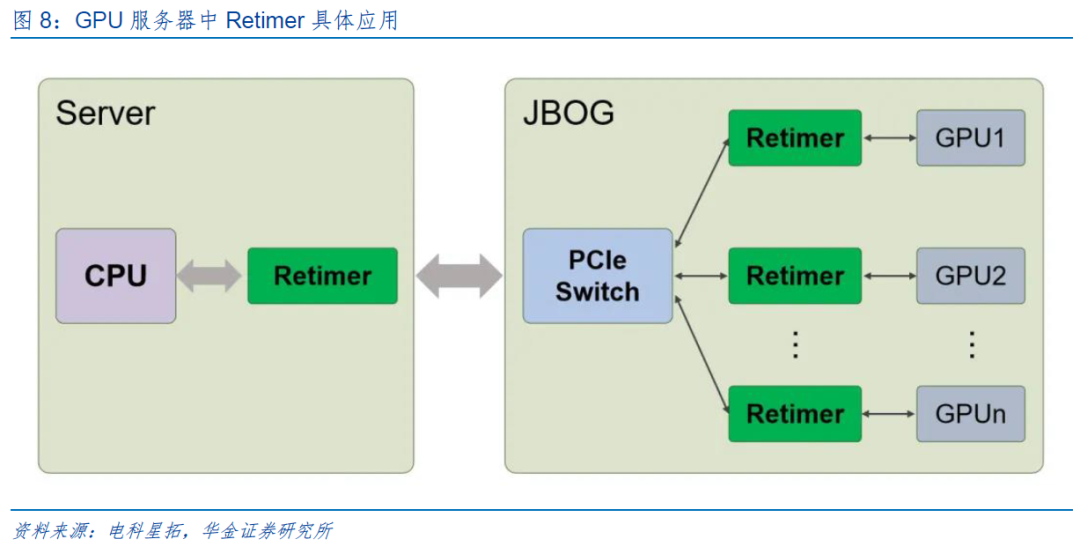
GPU服务器:GPU服务器通常配置有多块高性能显卡,以支持复杂的图形渲染、机器学习等计算密集型任务。在此类应用环境中,Retimer不仅可使GPU与CPU之间的高速数据传输更加稳定,还能有效延长GPU服务器的有效工作距离,使其在大规模分布式计算集群中发挥更大效能。
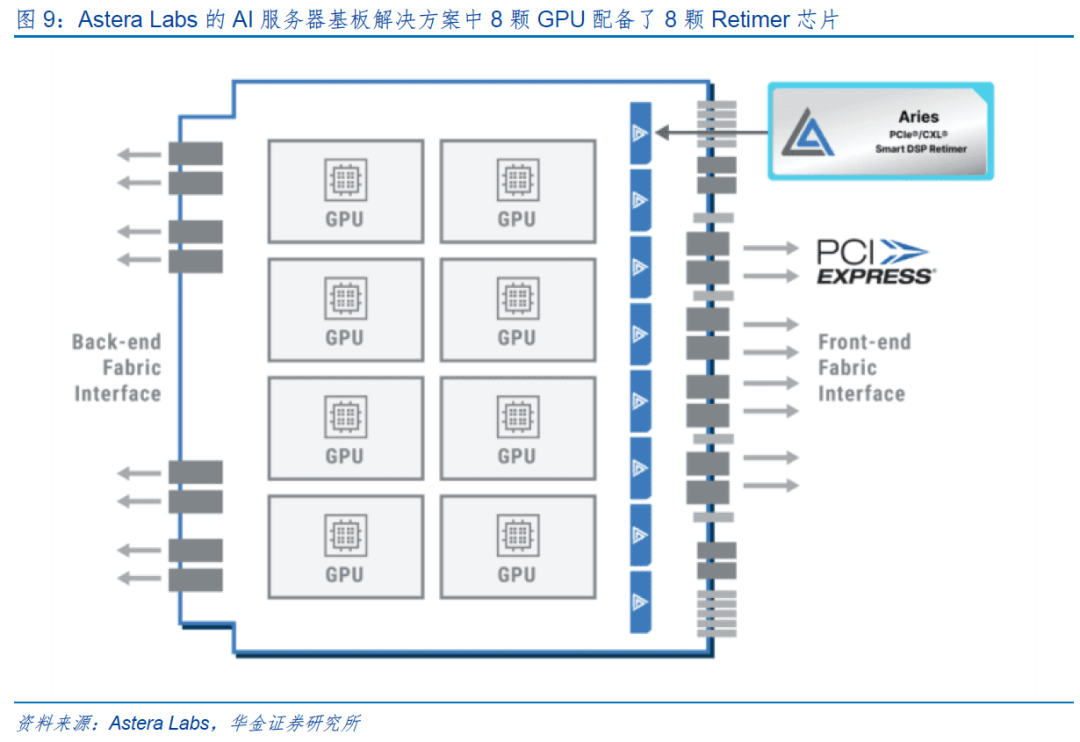
AI时代,随着AI服务器需求的快速增长,PCIe Retimer芯片的重要性愈加凸显。目前,一台典型配置8块GPU的主流AI服务器需要8颗或16颗PCIe Retimer芯片。未来,PCIe Retimer芯片的市场空间将随着GPU需求量的增加而持续扩大。
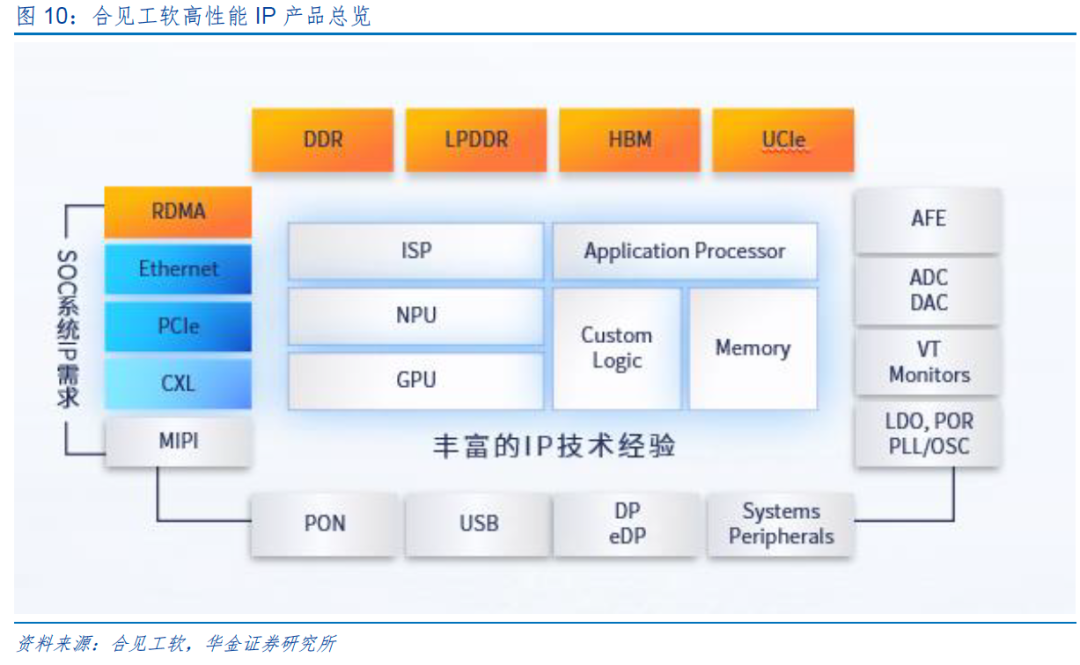
合见工软是国内首家可为数字大芯片设计提供“EDA IP 系统级”联合解决方案的供应商,现已推出多款高可靠性、高性能的网络IP、存储IP及D2D接口IP解决方案等,包括:针对芯粒集成的关键标准UCIe解决方案UniVista UCIe IP;面对存储接口,推出全国产Memory接口UniVista HBM3/E IP、UniVista DDR5 IP、UniVista LPDDR5 IP;为助力智算万卡集群,推出智算网络IP解决方案UniVista RDMA IP;面向网络接口,推出以太网、灵活以太网、Interlaken等多种高速互联接口控制器UniVista Ethernet Controller IP;以及推出全国产PCIe Gen5完整解决方案等。
合见工软股东包括澜起科技、卓胜微、韦豪创芯(韦尔股份旗下)、联发科、华勤技术等大厂。
2、CXL MXC 芯片
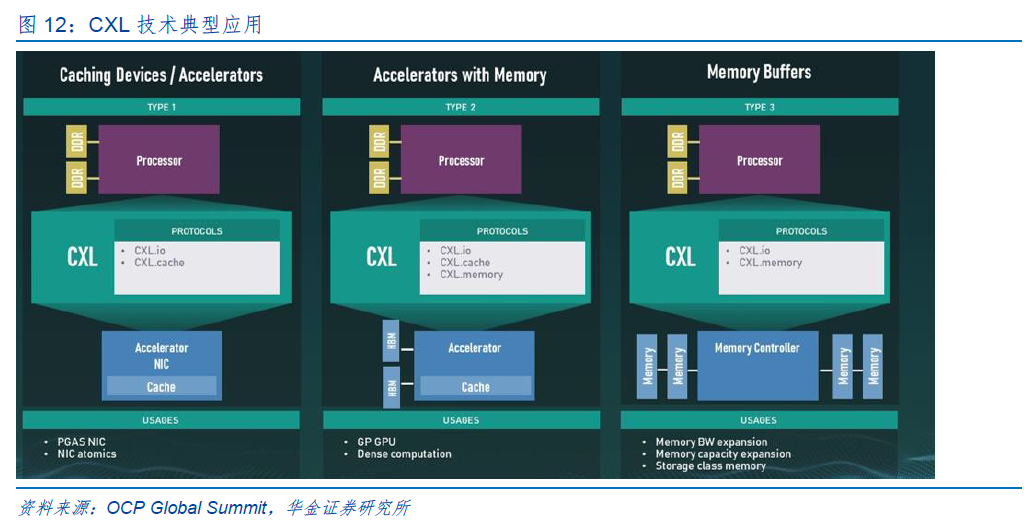
CXL(Compute Express Link)技术作为新型的高速互联技术,允许在计算机系统内部的不同组件之间进行快速、可靠的数据传输。此外,它还支持内存共享和虚拟化,使设备之间的协作更加紧密和高效。随着人工智能蓬勃发展,对支持快速接口和易扩展性的内存平台的需求愈发显著,而基于CXL的新型DRAM模块可能是未来人工智能时代中最具前景的内存解决方案之一。

自2019年英特尔将CXL技术从公司内部转移到行业联盟并首次公开讨论该技术,CXL技术正式进入公众视野,并开始了其标准化和推广的过程。经过数年的发展,目前CXL的生态已经初步形成。华为、英伟达、AMD、英特尔、三星、谷歌等大厂均已加入CXL联盟。根据Yole数据,全球CXL市场规模预计在2028年达到150亿美元。

在处理器互联方面,CXL技术可以实现不同厂商的处理器之间的互联,提高系统的整体性能和灵活性。Yole在2023年10月的预测中指出,尽管目前只有不到10%的CPU与CXL标准兼容,但预计到2027年,所有CPU都将被设计为支持CXL接口,这将进一步推动CXL市场的发展。
MXC,即Memory Expander Controller 的缩写,中文名称为内存扩展控制器,是基于CXL 协议的高带宽高容量内存扩展模组的核心芯片。该芯片支持JEDEC DDR4和DDR5标准,同时符合CXL 2.0规范,支持PCIe 5.0传输速率。该芯片可为CPU及基于CXL协议的设备提供高带宽、低延迟的高速互连解决方案,实现CPU与各CXL设备间的内存共享,在大幅提升系统性能的同时,显著降低软件堆栈复杂性和数据中心总体拥有成本(TCO)。
MXC芯片主要应用于内存扩展及内存池化领域,为内存 AIC 扩展卡、背板及 EDSFF 内存模组而设计,可大幅扩展内存容量和带宽,满足高性能计算、人工智能等数据密集型应用日益增长的需求。
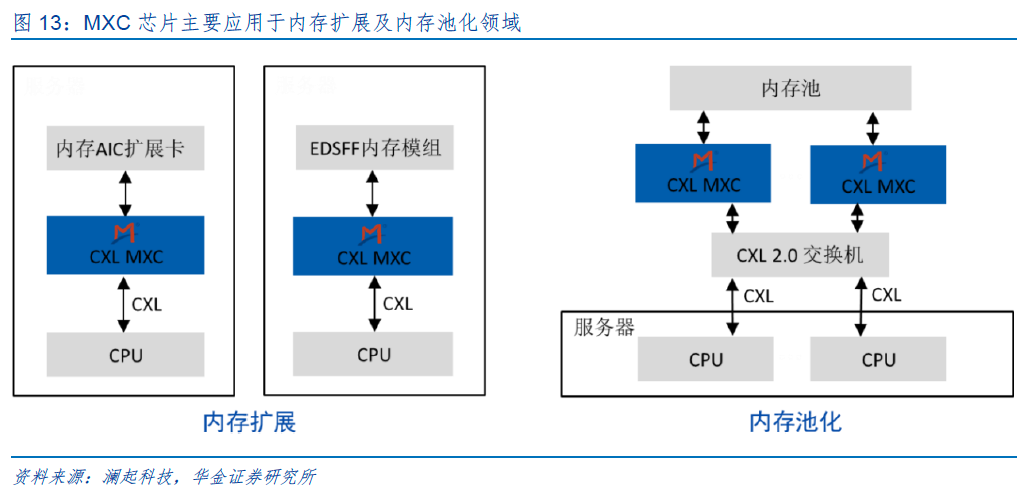
MXC芯片目前的产品应用形态主要有两种:EDSFF模组、AIC(Add In Card)连接标准 DDR5/4内存模组。


3、MRCD/MDB芯片
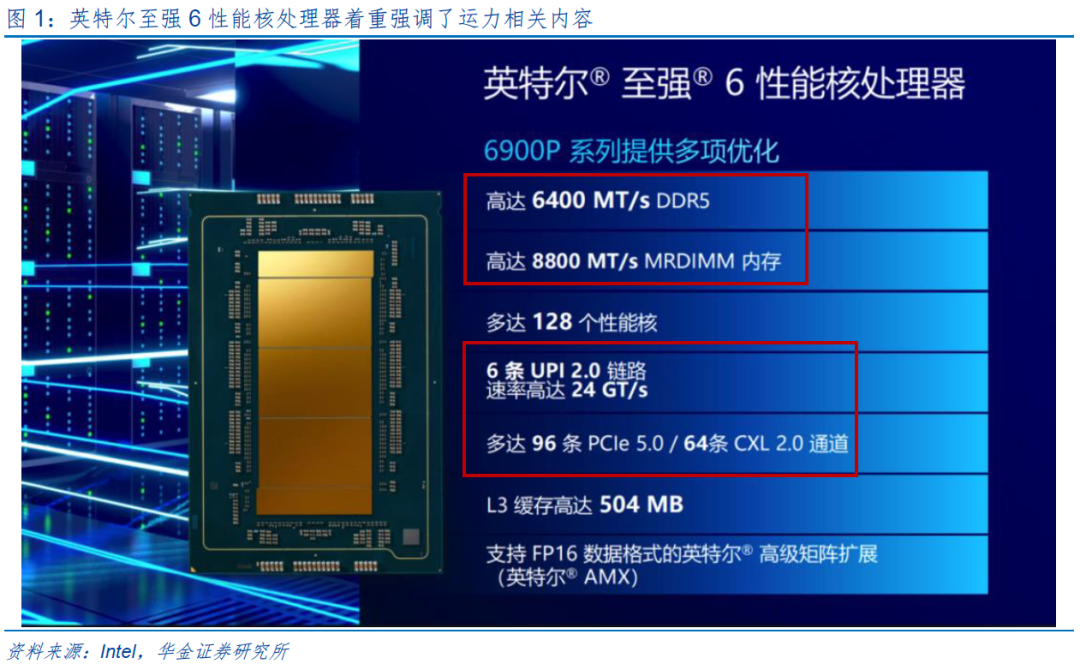
AI 及大数据应用的发展以及相关技术的演进推动服务器CPU的内核数量快速增加,迫切需要大幅提高内存系统的带宽,以满足多核CPU中各个内核的数据吞吐要求,MRDIMM正是基于这种应用需求而生。MRDIMM是一种更高带宽的内存模组,其特点和优势在于:(1)使用的是常规的DRAM颗粒;(2)与现有DDR5生态系统有良好的适配性;(3)可以大幅提升内存模组的带宽。英特尔至强6性能核处理器全新引入速率高达8800MT/s的MRDIMM,相比DDR5(6400MT/s),在科学计算和AI场景等多项任务中的性能提升7%-33%。
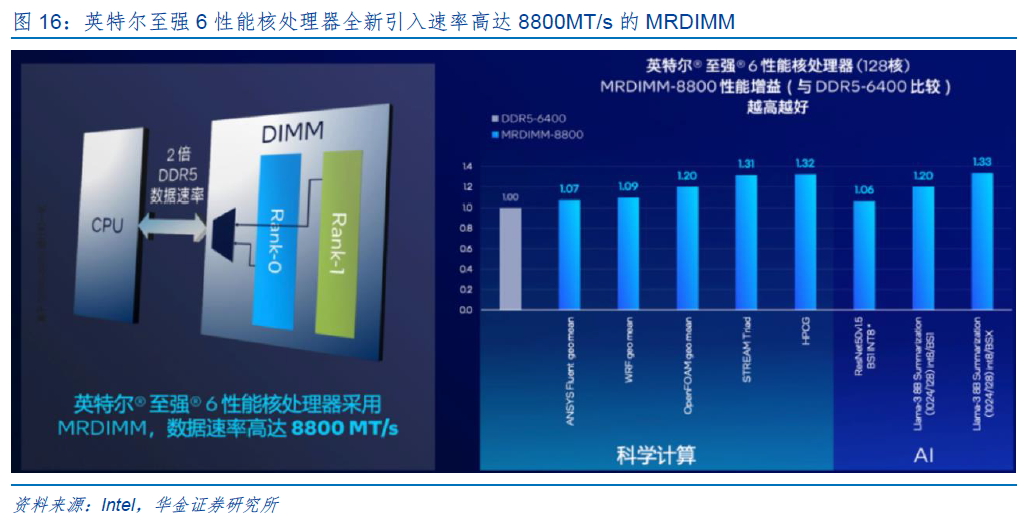
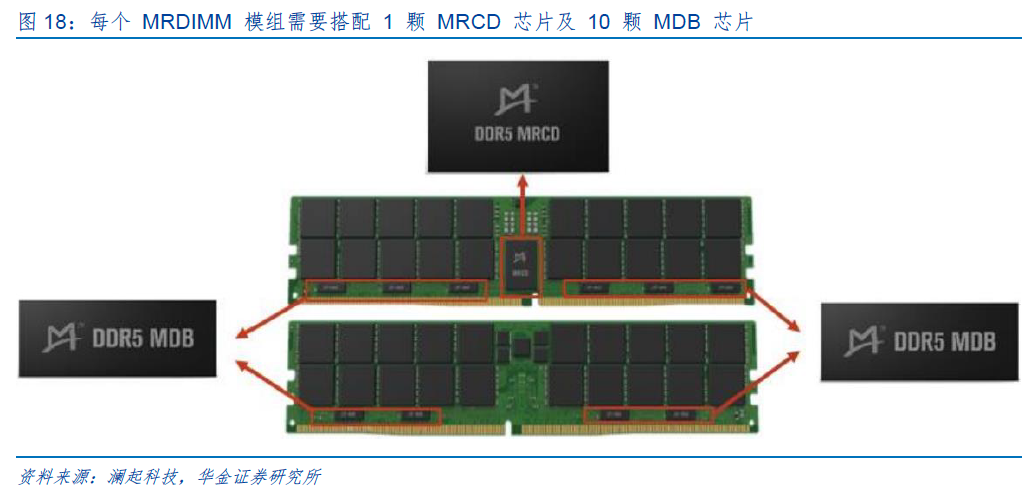
MRCD、MDB芯片是服务器高带宽内存模组MRDIMM的核心逻辑器件。MRDIMM工作原理为:MDB芯片用来缓冲来自内存控制器或DRAM内存颗粒的数据信号,在标准速率下,通过 MDB芯片可以同时访问两个DRAM内存阵列(RDIMM只能访问一个阵列),从而实现双倍的带宽。MRCD用来缓冲来自内存控制器的地址、命令、时钟、控制信号。
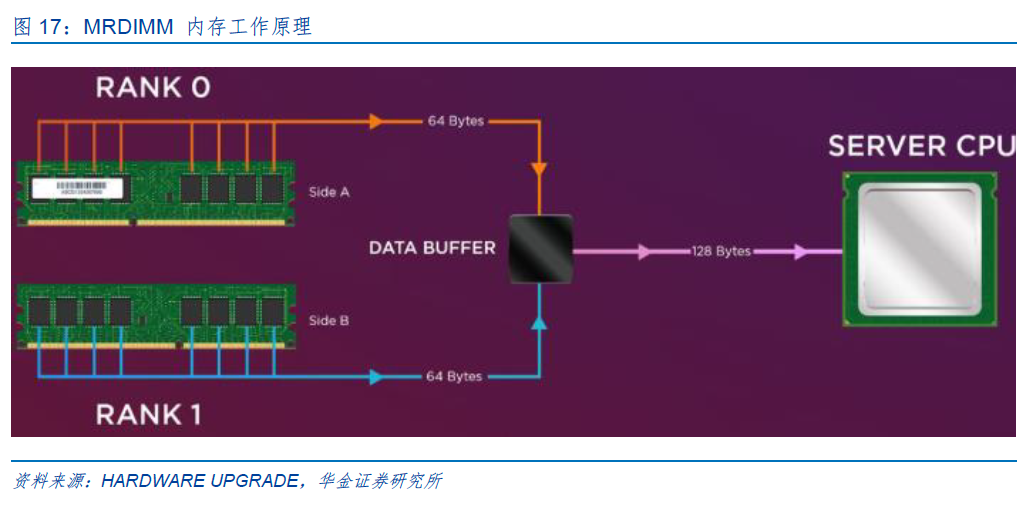
每个MRDIMM模组需要搭配1颗MRCD芯片及10颗MDB芯片。随着企业对高性能内存的需求日益增加,MRDIMM技术通过提高内存带宽和降低延迟,能够显著提升数据中心的整体能效,同时其兼容DDR5标准,便于在现有系统中进行升级和部署,使其成为未来数据中心内存技术的重要发展方向。随着MRDIMM未来渗透率的提升,将带动MRCD/MDB(特别是 MDB)芯片需求大幅增长。
4、NVLink传输
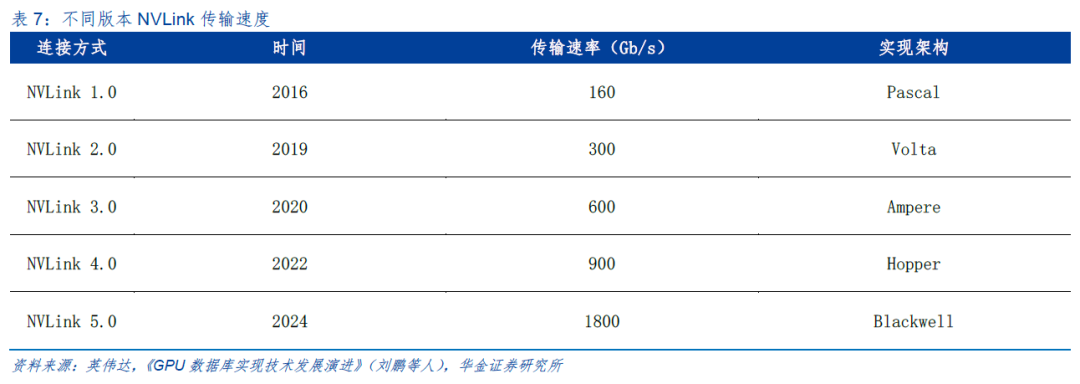
NVLink是世界上首项高速GPU互联技术,与传统的PCIe相比,它能为更多GPU系统提供更快速的替代方案。NVLink技术通过连接多个NVIDIA显卡。能够实现显存和性能扩展,从而最大限度的满足工作的负载要求。NVLink能在多GPU之间和GPU与CPU之间实现高速的连接带宽。NVLink控制器主要由3层组成,分别是:物理层、数据链路层和传输层。
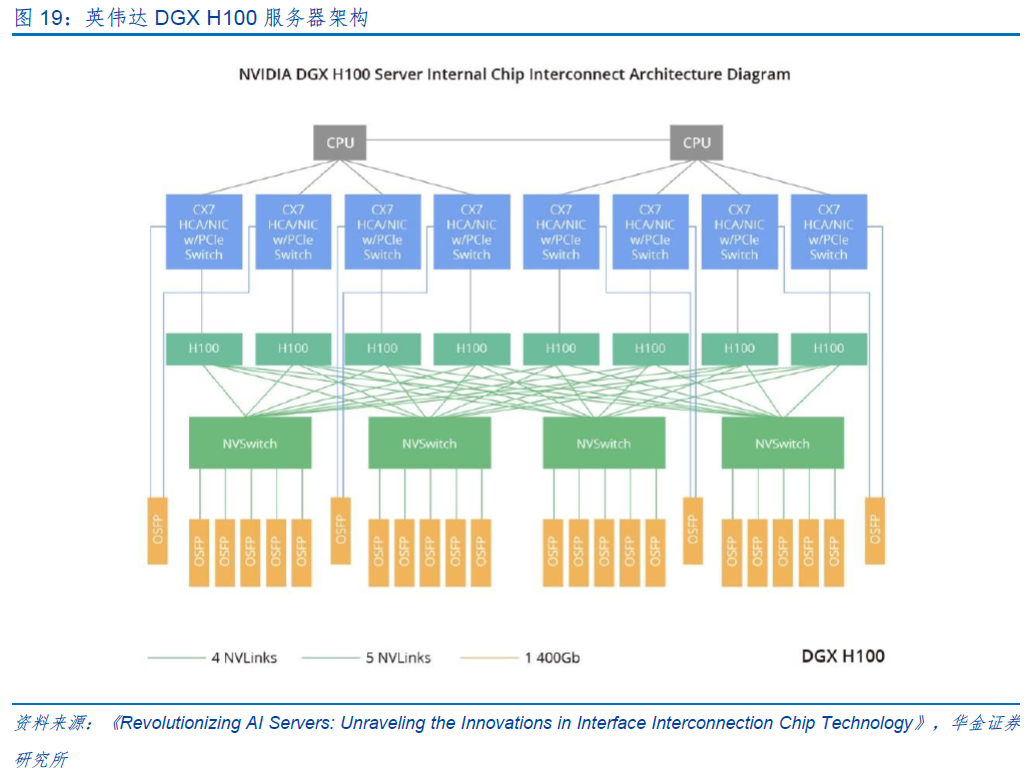
以DGX H100服务器为例,每个GPU向外扩展18个NVLink,实现每个链路双向带宽达到50GB/s,总共达到900GB/s的双向带宽。这些带宽分布在4个内置的NVSwitch芯片上,每个NVSwitch对应4-5个OSFP光模块。每个OSFP光模块使用8个光通道,传输速率为100Gbps/通道,因此总速率达到800Gbps,最终实现高速数据传输。
5、以太网
以太网,即Ethernet,是一种有线局域网通讯协议,应用于不同设备之间的通信传输。自1973年发明以来,以太网已历经40多年的发展历程,因其同时具备技术成熟、高度标准化、带宽高以及低成本等诸多优势,已取代其他网络成为当今世界应用最普遍的局域网技术,覆盖家庭网络以及用户终端、企业以及园区网、运营商网络、大型数据中心和服务提供商等领域,在全球范围内形成了以太网生态系统,为万物互联提供了基础。
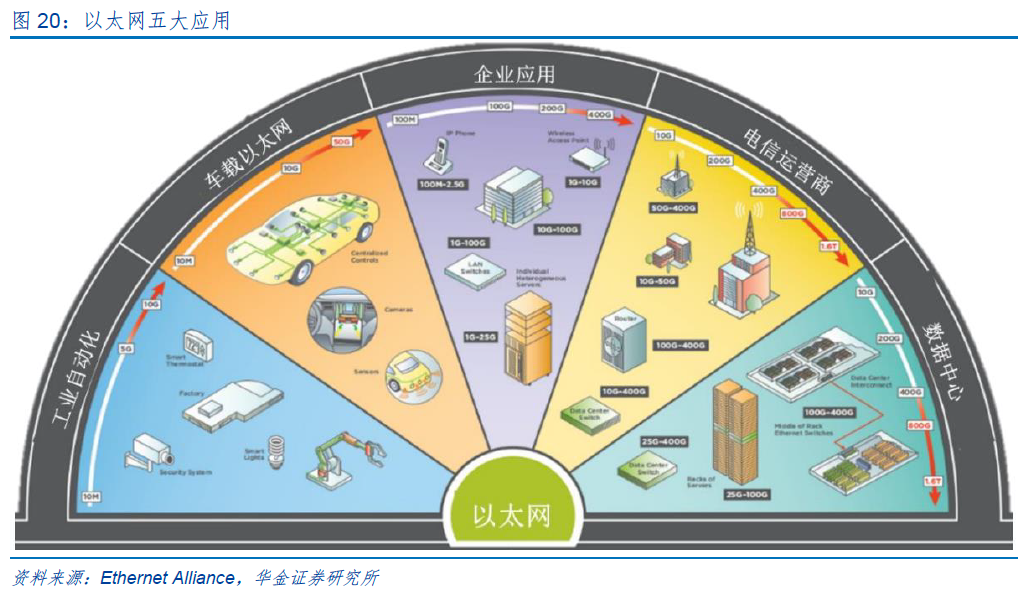

以太网传输介质可分为光纤和铜双绞线两类,其中10G以上多采用光纤。光纤具有传导损耗低、传输距离远等特性,被广泛用于长距离有线数据传输,应用场景主要涵盖电信运营商和数据中心等,但由于光纤质地脆、机械强度差、弯曲半径大且光电转换器材成本较高,终端数据传输较难取代铜线。铜双绞线机械强度好、耐候性强、弯曲半径小,同时无需光电转换设备即可直接使用,因而成为数据传输“最后一百米”的最优解决方案,是智能楼宇、终端设备、企业园区应用、工业控制以及新兴的车载以太网的主要选择。
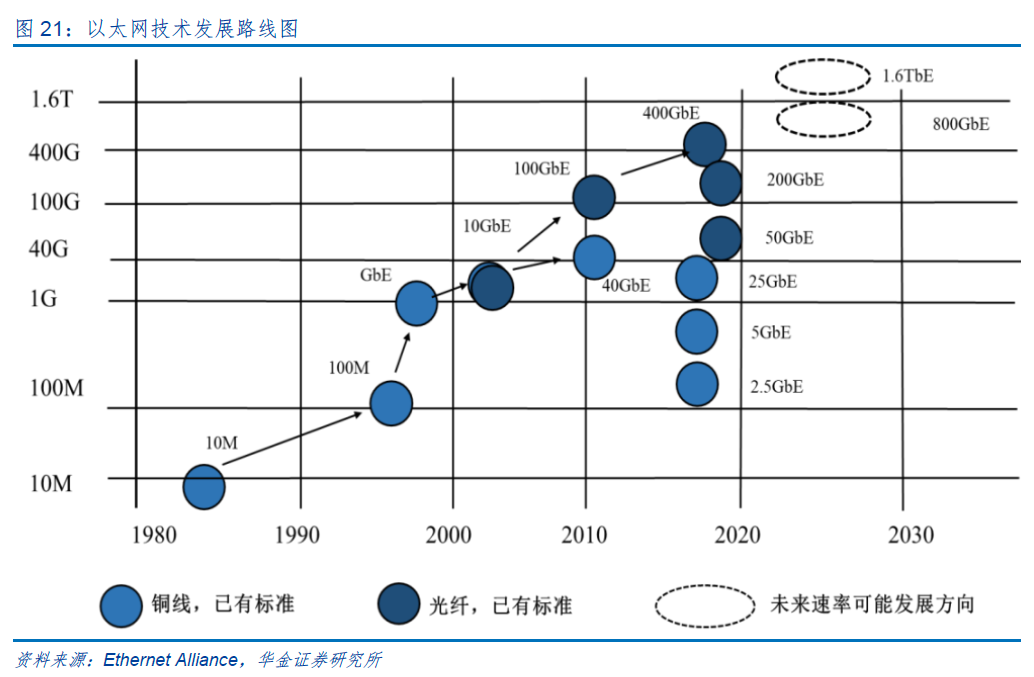
以太网已成为数据中心内部网的主要网络技术,几乎覆盖所有层级的网络需求,从服务器间通信到存储访问。
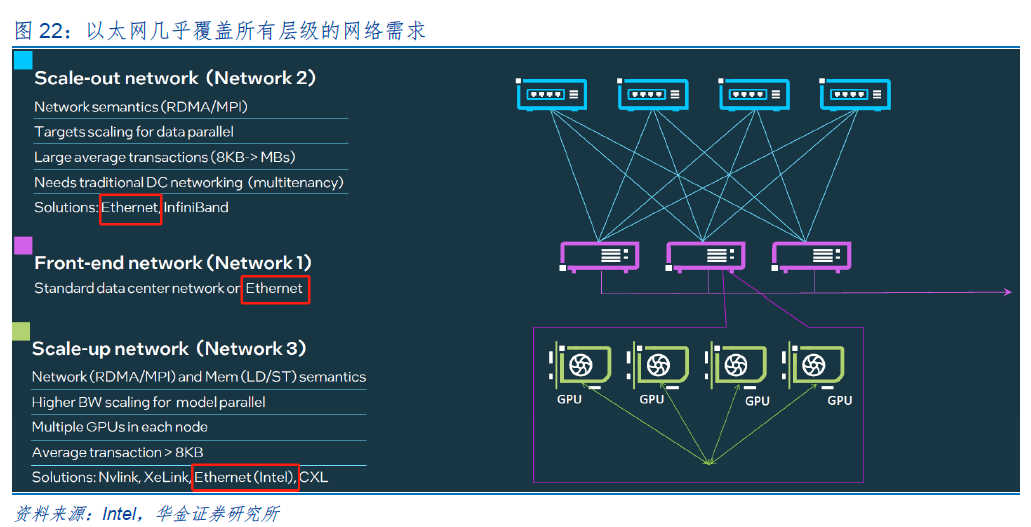
以太网交换设备为用于网络信息交换的网络设备,是实现各种类型网络终端互联互通的关键设备。以太网交换设备由以太网交换芯片、CPU、PHY、PCB、接口/端口子系统等组成, 其中以太网交换芯片和CPU为最核心部件。以太网交换芯片为用于交换处理大量数据及报文转发的专用芯片,是针对网络应用优化的专用集成电路。以太网交换芯片内部的逻辑通路由数百个特性集合组成,在协同工作的同时保持极高的数据处理能力,因此其架构实现具有复杂性。CPU是用来管理登录、协议交互的控制的通用芯片;PHY用于处理电接口的物理层数据。部分以太网交换芯片将CPU、PHY集成在以太网交换芯片内部。
三、建议关注
1、澜起科技
公司是一家国际领先的数据处理及互连芯片设计公司,致力于为云计算和人工智能领域提供高性能、低功耗的芯片解决方案,目前拥有互连类芯片和津逮®服务器平台两大产品线。互连类芯片产品主要包括内存接口芯片(含MRCD/MDB芯片)、内存模组配套芯片、CKD芯片、PCIe Retimer芯片、MXC芯片等,津逮®服务器平台产品包括津逮®CPU 和混合安全内存模组(HSDIMM®)。
公司近年来深耕相关互连技术,包括高带宽内存互连、PCIe互连以及CXL互连技术等,这些高速互连技术可以有效提升系统的“运力”,公司基于上述技术研发的几款芯片,包括MRCD/MDB、CKD、PCIe Retimer、MXC芯片等,将在未来的人工智能时代发挥重要作用。

津逮®服务器平台主要由澜起科技的津逮®CPU和混合安全内存模组(HSDIMM®)组成。该平台具备芯片级实时安全监控功能,可在信息安全领域发挥重要作用,为云计算数据中心提供更为安全、可靠的运算平台。此外,该平台还融合了先进的异构计算与互联技术,可为大数据及人工智能时代的各种应用提供强大的综合数据处理及计算力支撑。津逮®服务器平台主要针对中国本土市场,已有多家服务器厂商采用津逮®服务器平台相关产品,开发出了系列高性能且具有独特安全功能的服务器机型。

2、盛科通信
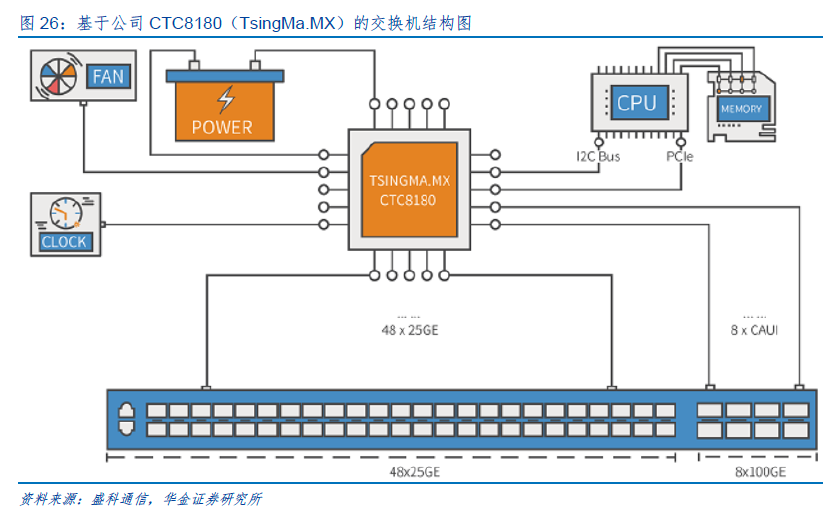
公司专注于以太网交换芯片及配套产品的研发、设计和销售,在国内具备先发优势和市场引领地位。公司目前产品主要定位中高端产品线,量产产品覆盖100Gbps~2.4Tbps 交换容量及100M~400G的端口速率,全面覆盖企业网络、运营商网络、数据中心网络和工业网络等应用领域。其中,TsingMa.MX系列交换容量达到2.4Tbps,支持400G端口速率,支持新一代网络通信技术的承载特性和数据中心特性;GoldenGate系列芯片交换容量达到1.2Tbps,支持100G 端口速率,支持可视化和无损网络特性;TsingMa系列芯片集成高性能CPU,为企业提供安全、可靠的网络,并面向边缘计算提供可编程隧道、安全互联等特性。
3、裕太微
公司专注于高速有线通信芯片的研发、设计和销售,以实现通信芯片产品的高可靠性和高稳定性为目标,以以太网物理层芯片作为市场切入点,逐步向上层网络处理产品拓展,目标瞄准 OSI七层架构的物理层、数据链路层和网络层。目前,公司已形成网通以太网物理层芯片、网通以太网交换机芯片、网通以太网网卡芯片、车载以太网物理层芯片、车载以太网交换机芯片、车载网关芯片、车载高速视频传输芯片七条产品线。其中网通以太网物理层芯片、网通以太网交换机芯片、网通以太网网卡芯片和车载以太网物理层芯片均已实现规模量产。
公司已自主研发出一系列可供销售的以太网芯片产品。根据网络传输速度的不同,目前市场上基于铜双绞线的独立的以太网芯片产品又主要可分为百兆、千兆、2.5G、5G、10G。

四、风险提示
下游需求复苏低于预期,算力基础设施建设进度低于预期,相关厂商研发进程不及预期,系统性风险等。

 VIP复盘网
VIP复盘网
